

What is SQL?
The term SQL stands for ‘Structured Query Language’, a domain-specific language used in data management. The language is used in relational database management systems due to its advantages in handling structured data and ability to incorporate relations among data.
What is a relational database?
A relational database organizes data in tables, and has the ability to handle complex relationships between different data points. Data is sorted into columns and rows, with a unique key identifying each row. Rows in the table can be linked to rows in other tables using these keys, allowing the relationships between sets of data to be tracked. Relational databases can use SQL to query and update the database.
Many businesses use SQL-based relational databases to store large records of information, so availability and data backup is vital.
What is SQL server replication?
SQL server replication is a method for duplicating and sharing data (and database objects) across multiple databases and servers. A single set of data stored in a SQL database is copied to a secondary server in a process known as master-slave replication. Any updates to the master database are made simultaneously to the additional server, aiming to enhance performance and preserve consistency.
This master-slave replication is a typical setup, but businesses can also employ master-master replication, which enables data to be copied from either server to the other. As SQL reads or writes can be performed from either server, access to data is more manageable and the possibility of data loss is greatly reduced.
Why use SQL server replication?
SQL server replication offers high availability by distributing data and objects from one database to another. There are several types of replication which can be used, including snapshot replication, transactional replication, and merge replication. Replication is usually used by mobile applications or server apps that are distributed and might have conflicts in their data.
SQL server replication is beneficial in a number of instances, for example, in data analysis where reports can be run on slave servers so the master database won’t be slowed down or corrupted. Data replication from single servers that are under large loads also supports scalability, increasing capacity and ensuring the speed of the master database is not affected.
SQL replication can also be replicated across different geographic locations. This provides an ideal solution for international businesses and increases the overall performance of the master database.
What is SQL server clustering?
SQL server clustering, also known as database clustering, is a high-availability solution where multiple SQL server instances (or nodes) are connected in a cluster, with access to a SAN (Storage Area Network) for shared storage.The SQL server data can be accessed from any instance, so if one node has an issue, you can seamlessly switch to a different node on the cluster.
Why use SQL server clustering?
When you are storing and processing critical data on your database, an interruption in access could cause significant issues. While you can take precautions to limit the risk of downtime, any infrastructure is liable to server or hardware faults or failures, which is where disaster recovery planning is essential. As a high availability solution, SQL server clustering ensures uninterrupted access to your data – in the instance of any issue with a server instance, another instance can take over.
Clustering is also beneficial for planned downtime of a node, for example if you wanted to run a security patch on one server instance, another node on the cluster can be used to avoid overall disruption of operations.
SQL server clustering additionally supports load balancing. If one server instance is under a heavy strain, another instance can take over some of the traffic, optimizing the performance of the nodes.
Replication vs clustering
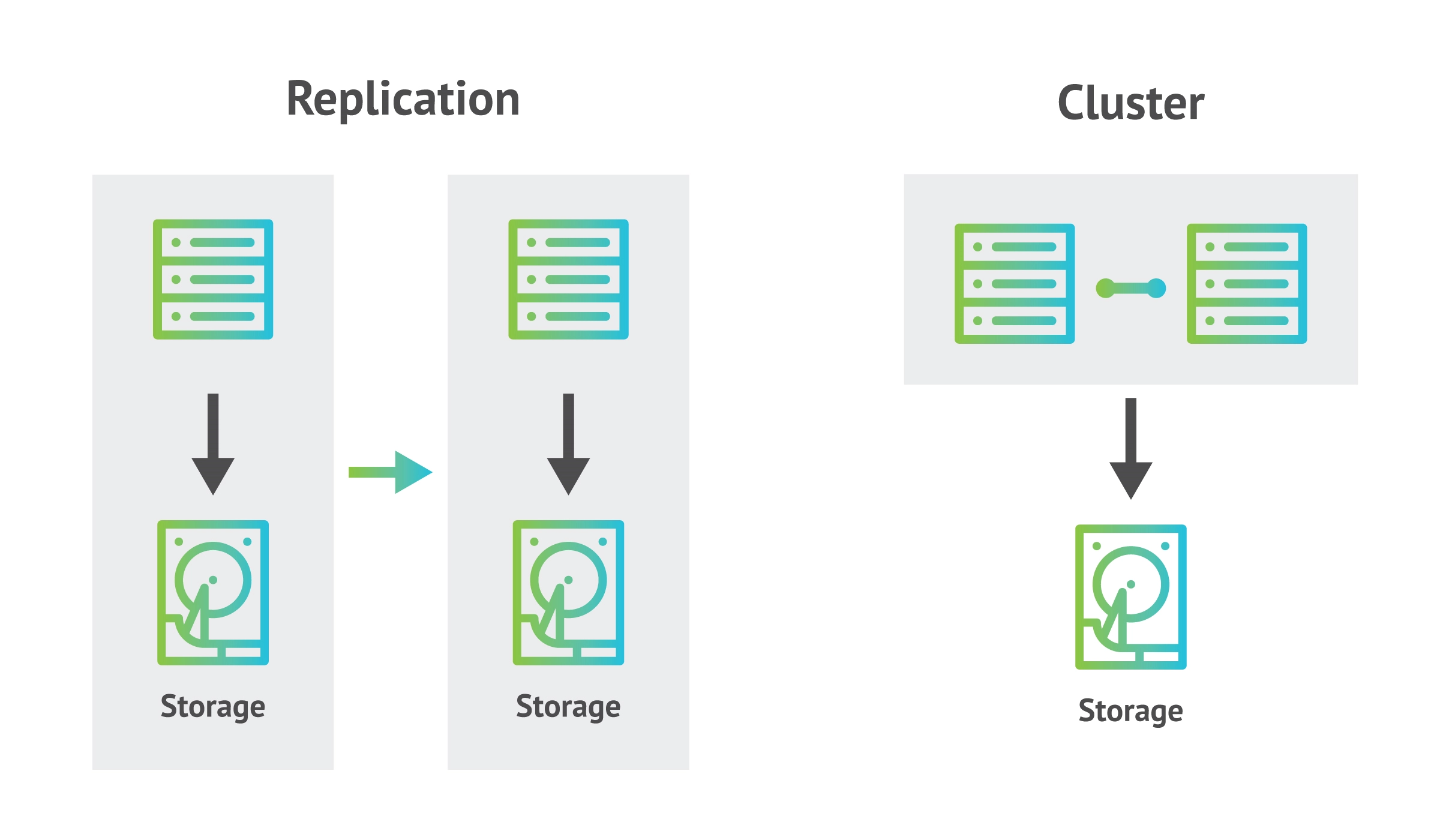
Both SQL server replication and clustering support high availability and disaster recovery in distinct ways. As a simplified explanation, replication backs up data across multiple databases and servers, whereas clustering connects multiple server instances with shared memory. Replication allows for data to be backed up and protected, and supports scalability and performance improvements, while clustering improves fault tolerance, allowing for seamless switching between server instances in the event of planned or unplanned downtime.
For important or high transaction applications we recommend a mixture of SQL server replication and clustering. This will give you complete automatic fail-over of databases as well as load balancing of transactions across multiple databases.
SQL server hosting with Hyve
Our flexible solutions allow you to connect SQL servers to hosted websites or to run intensive queries, manipulate data and set access controls. Whether you prefer to use MS SQL, MySQL, MariaDB, or any other SQL database, we can host and manage your infrastructure with top-of-the-line hardware, and 24/7/365 support and monitoring. Find out how our SQL hosting could benefit your business.
Speak to our cloud experts today for an initial consultation on the best SQL server hosting solution for you. Fill out our contact form and we will be in touch.



